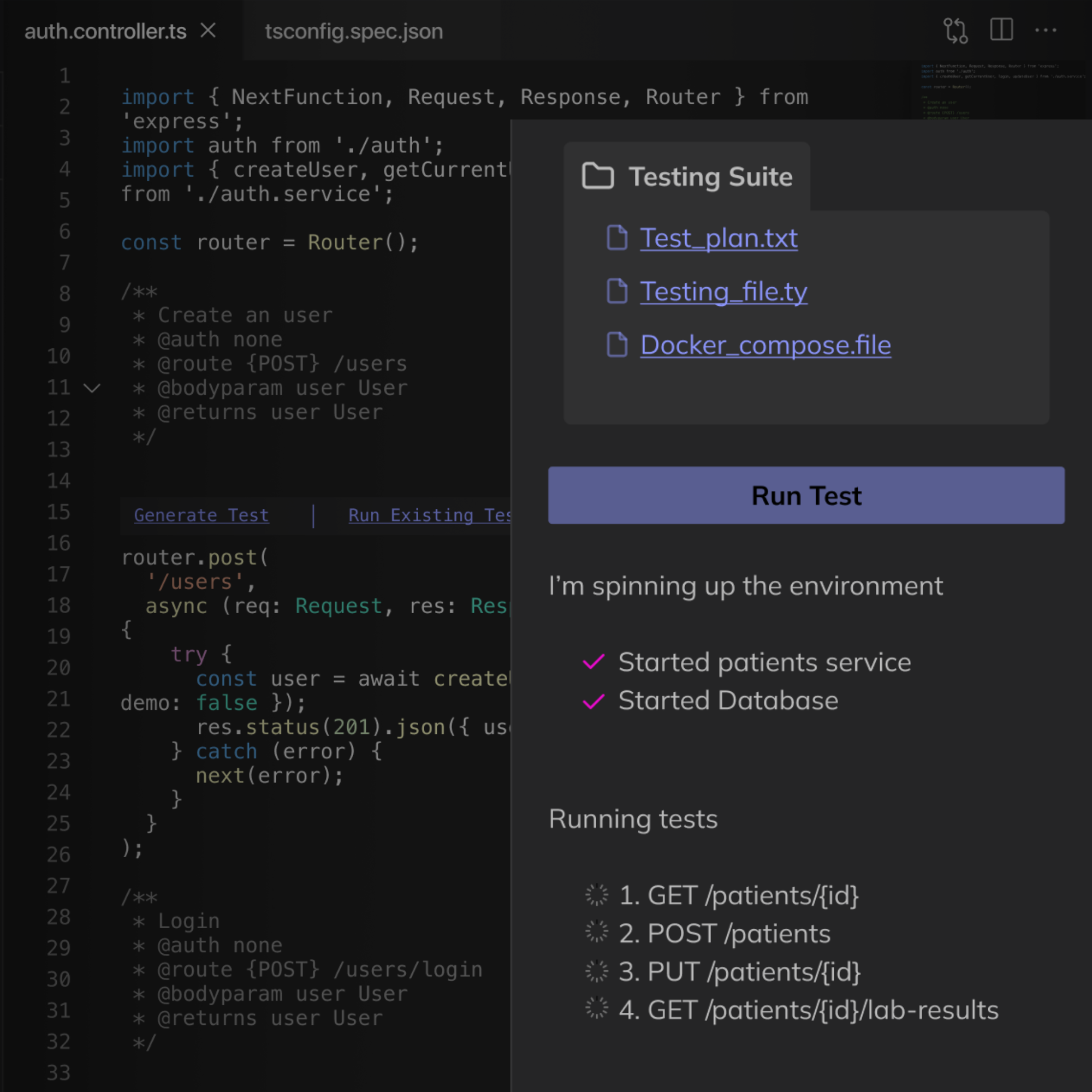
Kerno automates integration testing in your IDE to help you quickly validate the behaviour of every code change so you can ship faster with confidence.
.svg)


.avif)
Kerno fully automates the testing workflow, from generation to execution to maintenance, so developers never waste time writing or fixing boilerplate tests.

As your codebase evolves, Kerno continuously updates test files, eliminating the overhead of test upkeep and ensuring your suite never drifts out of sync.
Kerno brings testing directly into the IDE, giving developers feedback in minutes while they're in flow. No more waiting on CI pipelines.
Kerno is built with best in-class security practices to keep your code safe and secure at every layer.


.png)
Got more questions? Drop us a message in our community Slack — we’re happy to help.