
Introduction
When building with agents for the first time, one can very reasonably ask, “why evaluations?” Why do we focus so much on these graded exams for LLMs and agents? Why do we agonise over both their construction and their results? “Why datasets?” “Why should I be so concerned about bias?” To answer these questions, it is useful to take a step back and examine the traditional software development workflow and ask “why agents?”
The Logical Blueprint: Traditional Software Engineering
In an engineering context, a problem emerges to be solved with software. The problem and requirements of the solution are defined, decisions are made on architecture, the logic of the code is reasoned and the code is written. This code is then tested such that it meets the logic of the requirements (tests). Bugs that appear in either tests or production are then fixed both by intuition and reference to the logic of the code, PRDs and the problem.
Note that I have purposefully overused the word “logic” here. Traditional software builds a logical model to perform a task or make a decision.
The Statistical Paradigm: How Machine Learning Differs
There is an alternative way to approach computing that we used to call machine learning. It has had a recent, profitable rebrand. In this paradigm, we choose a mathematical algorithm (model) that will take an input and make calculations that lead to an output decision.
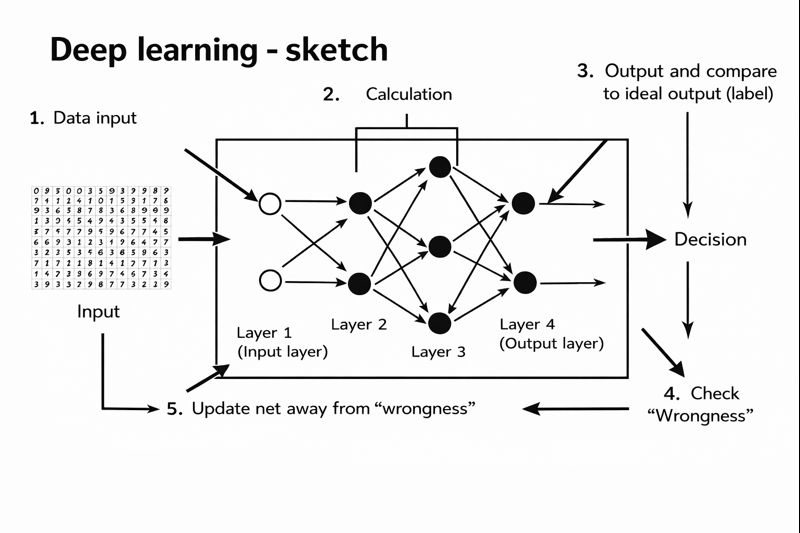
The algorithm necessarily has parameters that can be tuned such that the algorithm gives a different output for a given input. These parameters are tuned by “training”, where the model is run with input and known, expected output (labels), the divergence between the actual and expected output is evaluated, and the parameters are updated in such a way as to decrease this divergence. This is done many, many times over a large dataset in order to build a statistical rather than logical model. This is a simplified way that deep learning works, sketched in the figure below, which demonstrates at a very high level how you would train a neural network on a simple task such as recognizing handwritten digits.
Why Agents Aren't Just "Code"
AI agents belong to this second approach to computing. They are a statistical, rather than logical approach, and we use them when we need a statistical approach. To be clear, if a problem is more amenable to a logical approach, we would just write traditional software.
LLMs live in this statistical, rather than logical world. That is a feature of both their construction and their behaviour. For LLMs, and neural network-based models in general, the response curve is not usually smooth. A small change in input can cause a very large change in output, often where the previous small change in input only caused a small change in output. For now, LLMs are not necessarily deterministic, even when the temperature is low. The same input can generate different output each time it is run.
Agents are intended to work in a wide variety of cases, and the space of possible behaviour is usually large (again, if we could enumerate all of the behaviours in simple functions, we would just write that in code). For these reasons, guessing on the optimal construction of an agent is costly. However, we typically (hopefully) employ agents for tasks where data is abundant.
The New Workflow: Evals as the "Update Step"
For all the reasons above, when we want to build agents, and work with statistical models, we need to employ the ideas and methods from ML along with those of SWE.
- The Foundation: For an agent, we begin with a clear task and broad expectation of behaviour.
- The Dataset: We collect a sufficiently large, balanced dataset that represents this behaviour, covering both central and edge cases.
- The Success Criteria: We decide success criteria, based on some kind of functional form (does output code run, for example), based on a ground truth of what the output should be (the label), or based on a human or algorithmic judgement (i.e. LLM-as-a-judge).
This is what we mean when we talk about “evals”. Based on these evals, we make changes to the construction of the agent (the data pipeline in, the prompts, the tools available, etc) based on data, rather than on intuition. This is akin to the update step in ML. In some way, the technology has co-opted us to work in the same way as earlier algorithms did. The technology and media theorists of the mid-to-late 20th century should feel vindicated.
This argument should hopefully clarify for you, the reader, why building agents can feel very different from traditional software engineering, and why the field draws in methods from building models, even if you would expect to be done with thinking about how the models are built by the time you build the agent. In other articles in this blog, we will discuss some of these methods and ingredients in more detail.