.jpg)
Introduction:
In a recent post, I showcased the CLI tooling we’ve built to enable scalable, repeatable agent testing across a wide range of environments. This tooling allows us to stress-test agents under varied real-world conditions and compare performance consistently.
In this post, I’ll outline how we used that CLI to evaluate our Docker Compose Agent across 18 different codebases, and what we learned from the results.
Methodology
While I won’t go into the details of our proprietary scoring model, the high-level process was straightforward:
- We ran the Docker Compose Agent across 18 distinct codebases
- The full test run took ~8 hours
- Results were manually annotated to validate correctness and outcomes
- We used Cursor to visualize and analyze performance trends
This approach allowed us to assess success rates, failure modes, and runtime behavior across a representative sample of production-like setups.
Codebase Composition
By Framework
- NestJS
- Django
- FastAPI
- Express.js
- Koa
- Flask
- Next.js
By Runtime
- Python
- Node.js
- Bun
By Language
- Primarily Python and TypeScript
External Dependencies
Many of the tested codebases relied on real infrastructure dependencies, including:
- PostgreSQL
- SQLite
- MongoDB
- ClickHouse
- Couchbase
- MariaDB
- and others
This ensured the agent was evaluated against realistic Docker Compose setups, not synthetic examples.
Check out the video below.
The Results:
Across 19 runs, Docker Compose Agent runs 50% of the time.
Success vs Failure
- Majority of runs succeed
- Successful states are RUNNING and RUNNING_HEALTHY
- RUNNING_HEALTHY is the dominant steady state
- Failures are clean and binary
- All failures end in EXITED
- Failures consistently have valid=false
- No gray states
- No partial, degraded, or ambiguous outcomes
Latency
- Successful runs
- Fastest: ~50s–2m
- Typical: ~3–7m
- Long tail: ~9–12m+
- Failed runs
- Can fail early or late (up to ~17m)
- Latency is not predictive of success
Takeaway: Longer runtime does not increase success probability; failures are not timeout-driven.
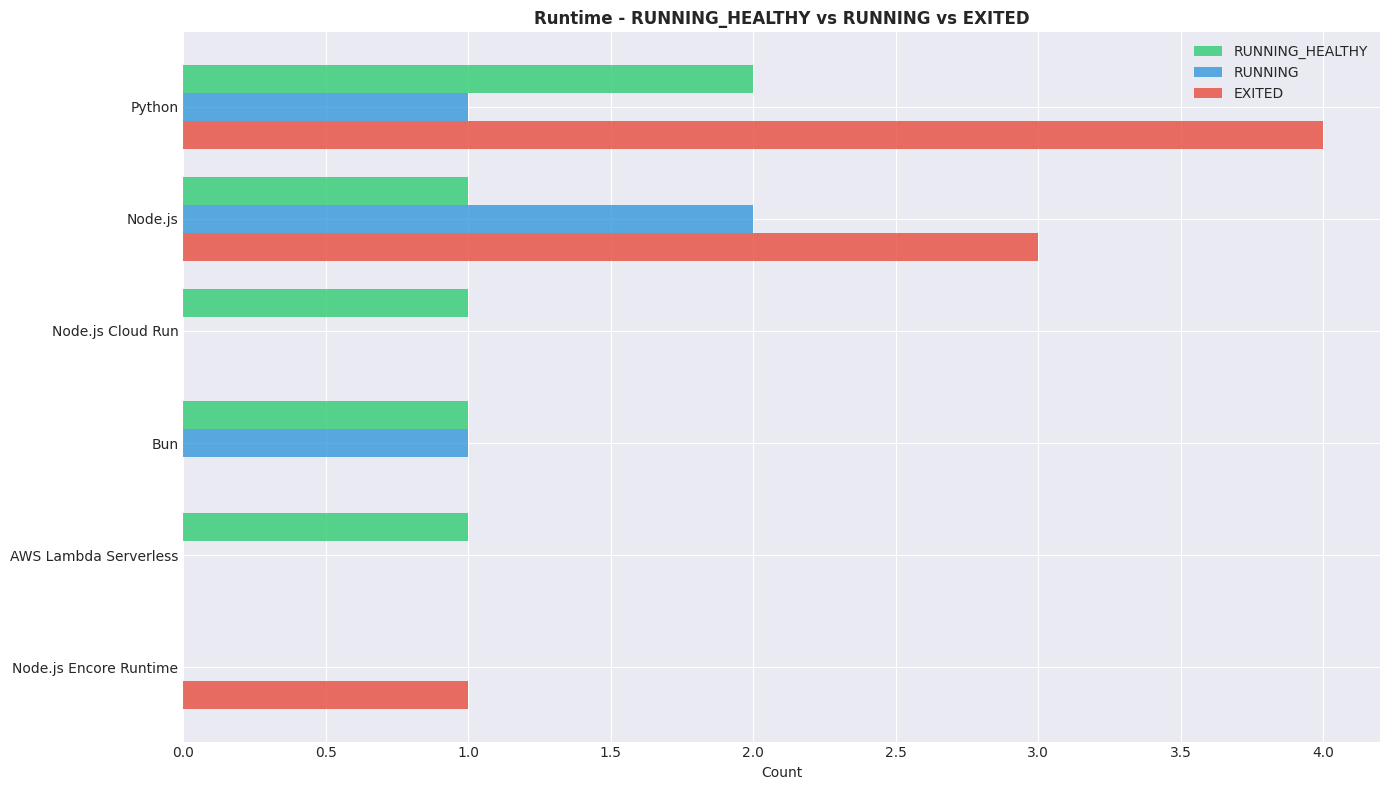
Runtime
- Docker-based runtimes (Python, Node.js) have the highest exit rates.
- Managed runtimes (Cloud Run, Lambda) show only healthy outcomes.
- Bun performs cleanly with no exits.
- Encore runtime consistently exits → likely unsupported or misconfigured.
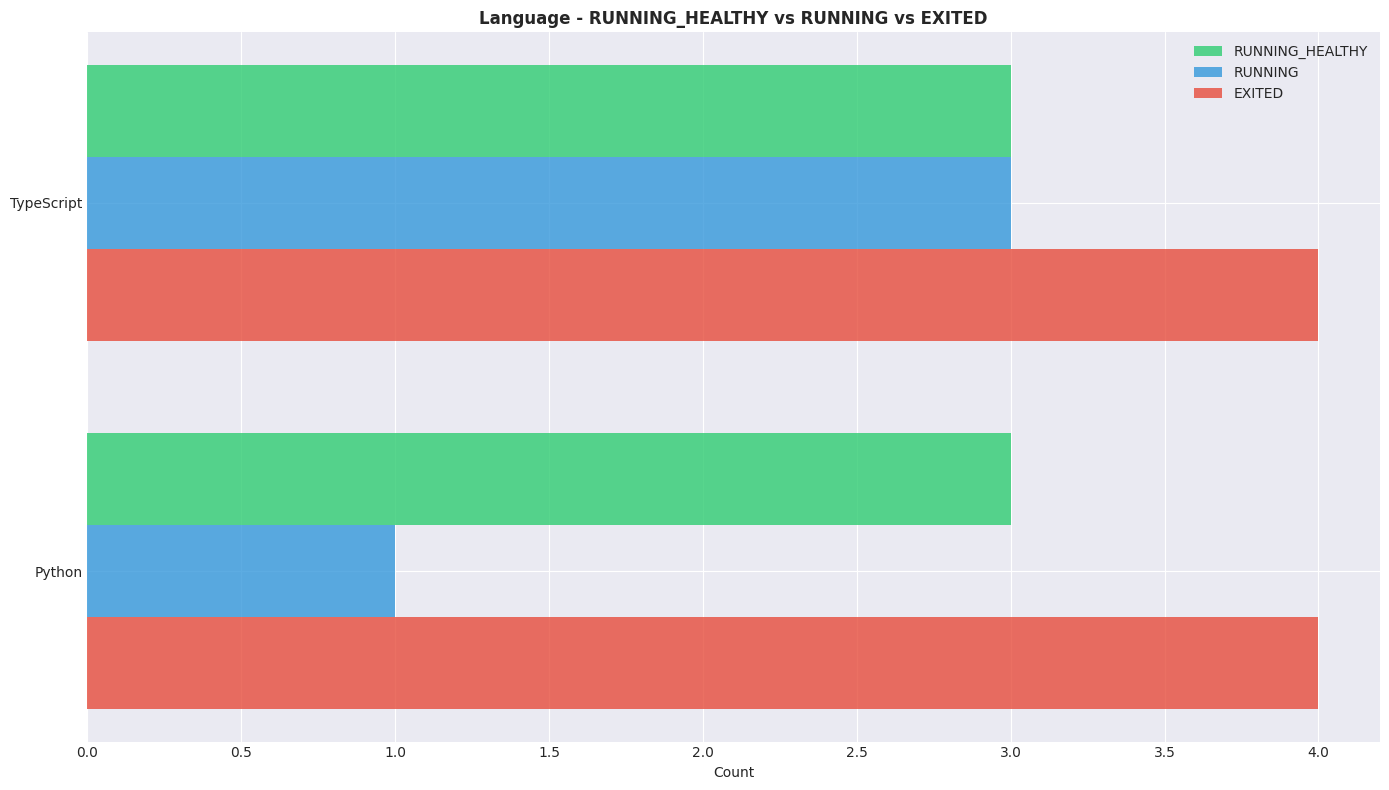
Language
- TypeScript has the strongest success profile despite higher volume.
- Python shows disproportionately more exits relative to successes.
Conclusion
The current 50:50 success:fail rate could be down the following
- Docker File Dependency: A key finding was that success rates are much higher when a Dockerfile is present in the repository, and the agent often fails or gives up when there is no Dockerfile.
- LLM Behavior: The LLM was observed to go into loops, spending a long time trying to fix or build a Docker image, especially when no Dockerfile exists.
Next steps:
- More tests and increased logging
- Proposed Solution: The developer suggested splitting the Docker Compose agent's role, with a separate agent dedicated to creating a valid Dockerfile, to improve the overall performance of Docker Compose generation.
- Context Missing: The LLM was noted to be missing a lot of context, and there is suspicion that it may not be correctly accessing existing Dockerfiles and Docker Compose files.