
When you can't define a correct answer as an exact string, you still need to measure whether your agent is behaving correctly. LLM-as-a-judge fills that gap: a second model evaluates the quality of a first model's output by treating assessment as a natural language task. This article covers when to use it, how to configure it reliably, and where it breaks down.
What LLM-as-a-Judge Actually Does
LLMs encode statistical correlations across a large text corpus and are fine-tuned to produce output matching human expectations for a given input. A judge LLM exploits this: given a question and a candidate answer, it estimates whether that answer is the kind of thing a competent human would accept—not whether it is factually true.
The distinction matters. A judge cannot verify ground truth. It can estimate plausibility relative to its training distribution and human preference signal. That makes it a reliable proxy for many evaluation tasks, but not a replacement for execution-based or string-match evaluation where those are available. Use LLM-as-a-judge when you have open-ended output and no computable success criterion.
For code-related agent tasks, research suggests LLM-as-a-judge performance approaches human evaluation quality, which makes it viable for automated quality gates at scale.
Implementation Guidelines
When considering to implement an LLM-as-a-Judge strategy, consider the following:
- Be explicit about the evaluation target. Vague prompts produce inconsistent judgements. Define precisely what the judge is measuring; correctness, relevance, tone, completeness.
- Set temperature to 0. Reproducibility is mandatory for an evaluation system. Non-zero temperature introduces variance that makes run-to-run comparison meaningless.
- Use categorical output, not numerical scores. LLMs produce more stable output when choosing from a discrete set of categories (e.g., incorrect / partially correct / almost correct / correct) than when generating a score on a continuous scale. Map categories to numbers after the judge returns its result if downstream aggregation requires it.
- Manage context window position. Attention is not uniform across the context window. Models give disproportionate weight to tokens at the start and end. Put critical instructions and evaluation criteria at one of those positions, not buried in the middle.
- Use a different model than your agent. A model evaluating its own output exhibits self-reference bias - it over-rates outputs that match its own generation patterns. Use a different model family, or at minimum a larger model in the same family.
- Use voting for high-variance tasks. For ill-defined or variable outputs, run multiple judge instances and aggregate with a Borda count: map categorical judgements to scores, sum across judges, and normalise by judge count. The number of judges needed depends on output fuzziness. Start with three and experiment. Note that multi-judge setups at frontier-model scale add meaningful cost and latency; weigh this against whether the judge is running in a continuous QA loop or only for benchmarking.
Validating the Judge Itself
A judge is software with the same failure modes as any other component: it can overfit, it can have coverage gaps, and it can behave unexpectedly on edge cases. Treat it accordingly.
Before deployment, write the judge against a small labelled dataset that covers representative outputs and edge cases - the same inputs your agent is likely to encounter in production. A few dozen examples is usually sufficient. Iterate until the judge produces appropriate verdicts across that set, but avoid tuning to it so tightly that it fails to generalize.
Once the judge runs against larger experiments or enters production, sample its outputs and review them manually for a period. This catches overfitting and surfacing systematic errors before they corrupt a benchmark run.
Reference Implementation: Langfuse
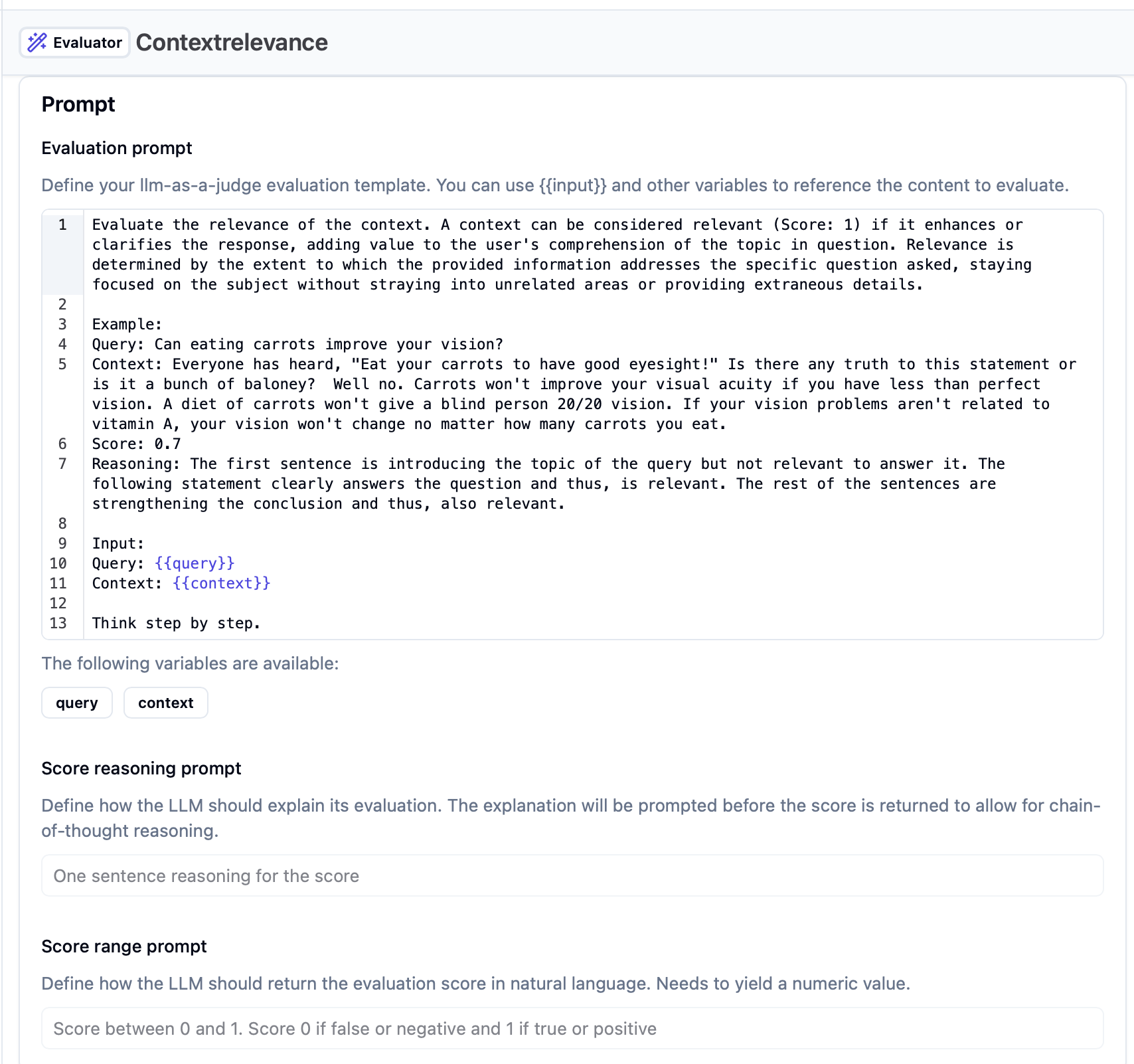
Langfuse maintains a library of pre-built judge templates covering common evaluation types: correctness, conciseness, context relevance, and toxicity, among others. Each template shows the structure of a well-formed judge prompt: explicit task definition up front, structured output specification, and input fields passed as f-string variables.
To explore them: open a project in Langfuse → click LLM-as-a-Judge → click Create evaluator. The templates are worth reviewing as a catalog of what kinds of things are worth measuring in agent output, even if you write your own implementation.
One structural note: Langfuse defaults to numerical scores. Override these with categorical outputs for the reasons above; templates make this straightforward to modify.
We use Langfuse for trace capture, experiment organisation, and dataset management rather than for its built-in judge execution, but the template library is a useful reference when designing evaluation criteria for a new task type.
Where This Breaks Down
- Factual verification. A judge cannot determine whether a claim is true—only whether it sounds plausible given its training distribution. For tasks where correctness is verifiable, use execution-based evaluation or string matching instead.
- Out-of-distribution outputs. If your agent operates in a highly specialised domain underrepresented in the judge model's training data, the judge's plausibility estimates will be unreliable. Validate on domain-specific examples before trusting at scale.
- Cost and latency in production loops. Multi-judge setups using large models are expensive. Running LLM-as-a-judge in a CI/CD gate on every PR will introduce meaningful cost and latency. The recommended deployment pattern is: string-match and execution evals in CI, LLM-as-a-judge in nightly or pre-release benchmark runs.
Getting Started
The fastest path to a working judge: take an existing Langfuse template for the evaluation type closest to your task, adapt the system prompt to your domain, outline categorical output, and run it against a small 20–30 labelled dataset. From there, it's about iterations. Understanding what is the meaured agreement. If agreement is below let's say below 70%, tighten the evaluation criteria in the prompt and rerun until it hit's the acceptance score.
For more articles on LLM-as-a-Judge, eval frameworks and testing pipelines, check out more of our articles from the AI Builder Series here.