
Introduction: Why Bubble Talk Matters—and Doesn’t
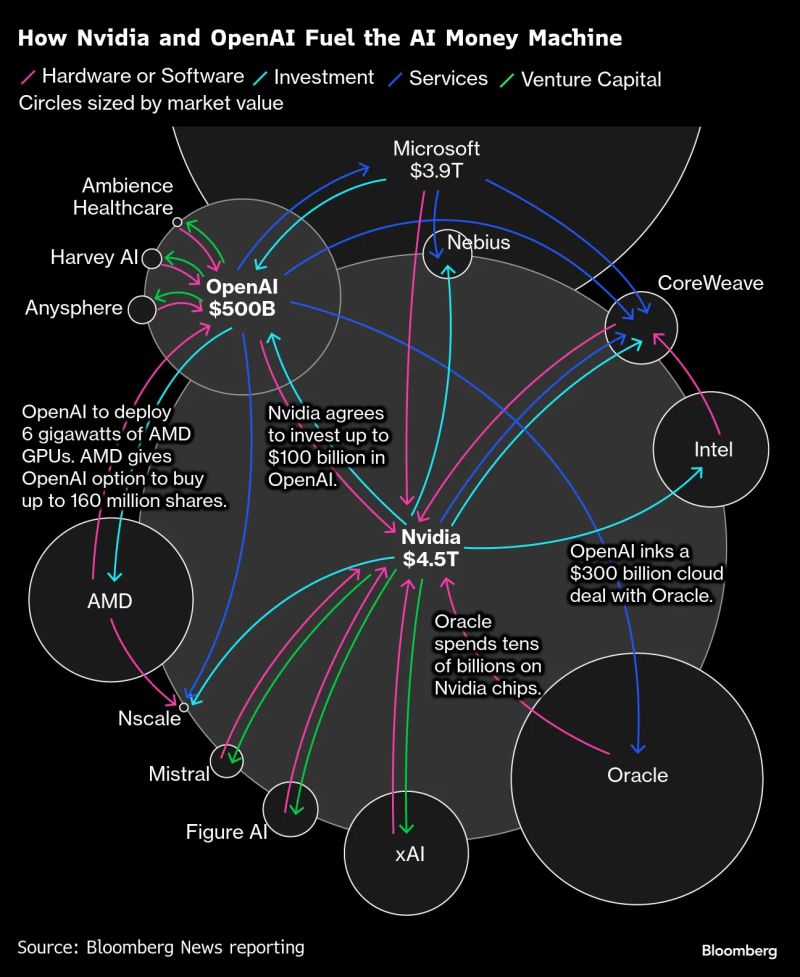
Much of the attention of the financial and tech press for the past few weeks has been on the subject of a possible AI bubble, not unlike the Dotcom bubble, when that might pop, and what that might look like. See for example the charts below from Bloomberg.
From the point of view of an AI builder, I'm going to outline here why some of the things the financial and tech press discuss with regards to the bubble do not necessarily matter to us, and what we're thinking about instead. To frame this, we note that a sensible strategy for any company is to build a product that people want to pay for, and deliver it at a price that allows you to make a profit. We may even look at profit as a constraint rather than a goal (a point Rory Sutherland from the Spectator has made).
Why an AI Bubble Is Largely Immaterial to Builders
In some ways, a bubble in the industry is immaterial to this. A bubble is about public and private investments that can't be recouped from later cash flows. Analysts have become particularly worried about this bubble because the spending involved is now responsible for much of the growth in the US economy, and an end to it could bring about an uncomfortable recession. Some economists argue that the sheer size of the bubble would cause problems that would propagate through the economy if it pops or deflates. Others have argued that this is less likely because the AI bubble is being financed more by current revenue of the large tech companies than the massive debt involved in past bubbles. There is also just a lot of wealth searching for a place to be deployed well (see buybacks, growth in M2 money supply, large cash positions of big names ranging from Apple or Berkshire Hathaway).
These things don't concern builders per se. When it comes to AI products, bubble or not, people will still use any product that they find value in. If the bubble pops, fundraising will still be possible because of the sheer amount of un-deployed wealth mentioned earlier looking for a return. The pain will be felt in share price and ability for companies to borrow on open markets. If you have a real product that can viably make money, you'll be fine.
Framing the Real Problem: Value vs. Cost
More easily said than done, however. Making a viable product depends on (A) how much people will pay for it and (B) how much it will cost to provide that product. (A) is really dependent on a lot of factors that re not entirely relevant to the bubble talk. It really depends on how much value your product provides, market size, and how tight economic conditions are. (B) is very dependent on the bubble, because the cost of tokens and inference matters a lot, and there are several interconnected factors across both the finance and the technology elements of the bubble that influence this.
1. Token Usage Is Being Massively Subsidised
Probably most importantly - everyone's token usage is being massively subsidised by the foundation model companies. From some excellent reporting from Ed Zitron, the model builders are losing a lot of money by undercharging for their products. Worse still, OpenAI's own cost of inference is being subsidised by Microsoft, as they are charged between 1 and 3 times less for compute than other enterprise customers. This can't continue, and some day soon we may well have to pay much more for the use of any AI tools based on GPUs.
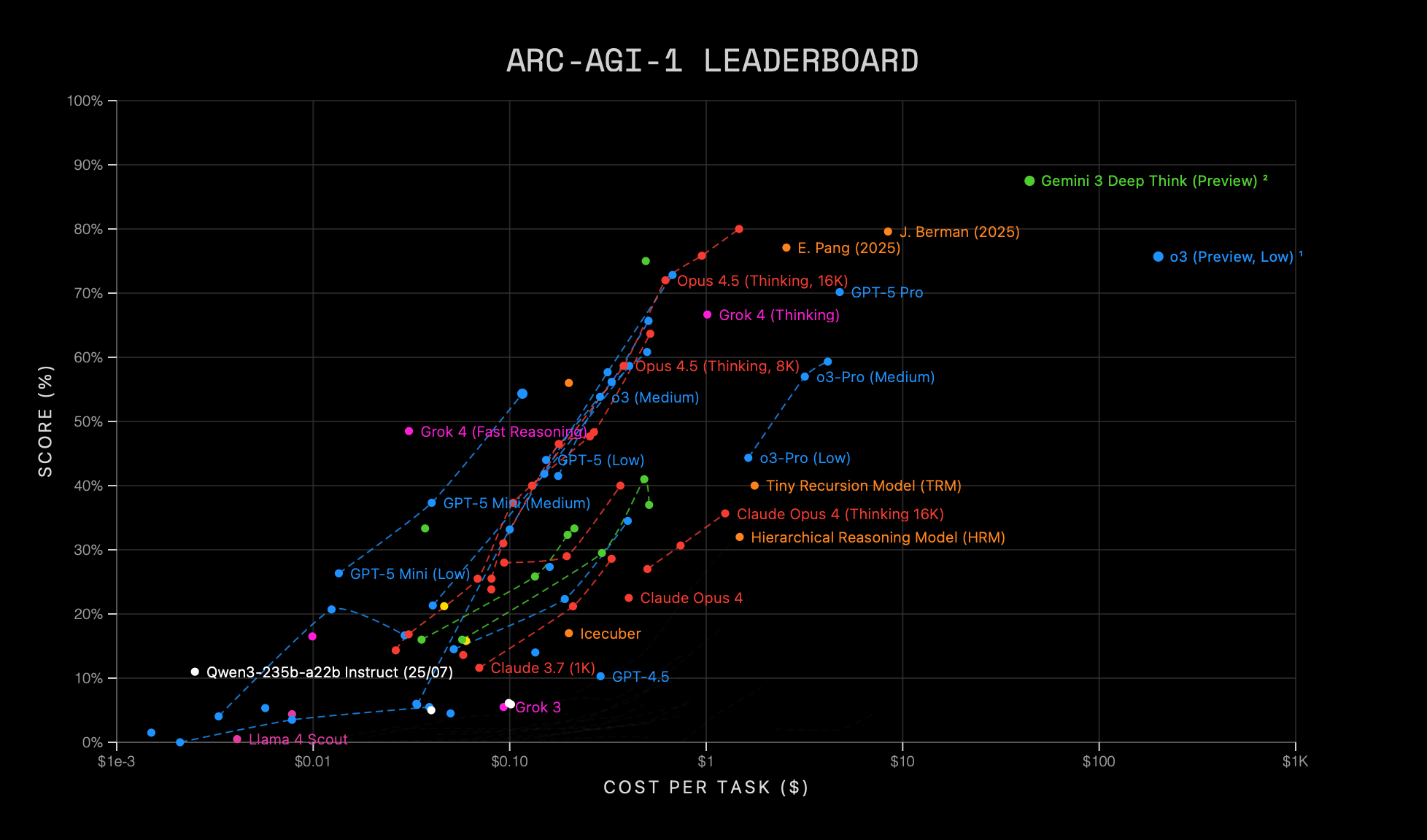
2. Scaling Has Ended
Scaling has ended (which any physicist would have told you it always would). See the ARC AGI leaderboard. It looks very much like logistic growth of capability vs. cost - and that's with cost on a log scale. Instead, improvements are being made through the use of reasoning models - running jobs through a model multiple times. This is very expensive.
3. Efficiency Gains Through Distillation and Smaller Models
In contrast, there are efficiencies to be gained either by model distillation (making the models smaller). Many parameters (think "parts") of frontier LLMs are redundant, but you can't know this when initially training them. Large efficiency gains can be made by systematically removing these. You can also use lower precision in the calculations of the models. Deepseek does this. It can also lead to improvements in other types of software, like climate models. Or you can use smaller models, trained for specific tasks. We think the field will look much more like this in a few years time. At present, OpenAI says that some of its larger models use a router model to choose which of a list of smaller models to use for a task. However, it is difficult to predict what the performance and cost of models will look like in the coming years. Just two years ago, some in the field were convinced that scaling would continue forever.
4. LLM-Based Software Does Not Scale Like Traditional Software
LLM based software does not scale in the same way as other traditional software does. For a database technology, or a website, or anything hosted on a user's machine (like anything from Adobe, Microsoft Office or Mathworks) the marginal cost of new users is either near zero, or scales sub-linearly. For LLMs, this is linear. Every new user costs you money.
5. Physical Infrastructure and Energy Constraints
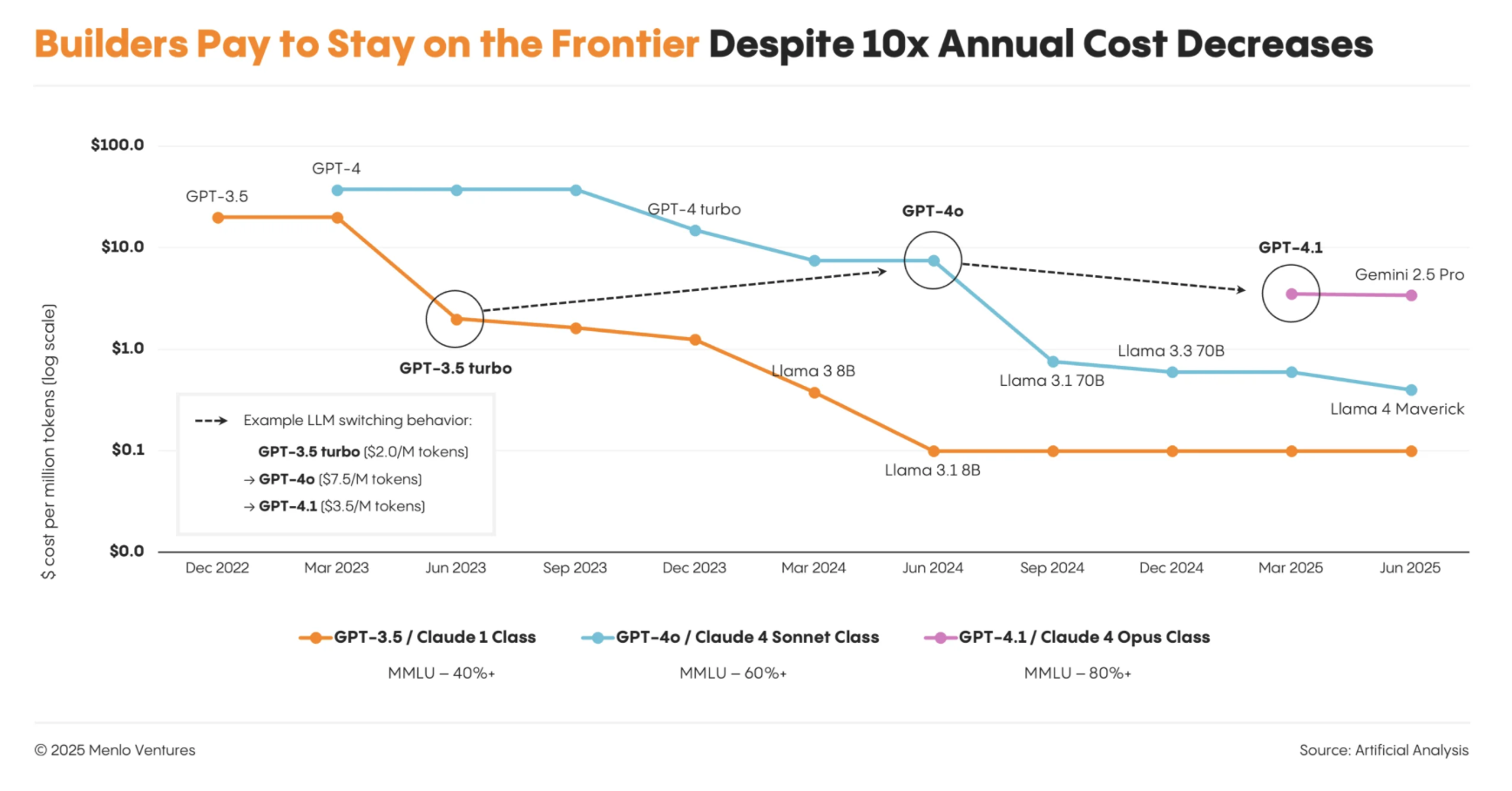
Bookending this list is another very important factor - the constraints of physical infrastructure and especially energy. This is the point that the press has mostly focussed on in the past few weeks. There is clearly a difficulty in building enough physical infrastructure to satisfy users' demand (or predicted demand) for AI products. Any of the factors in point (3) may not help with this due to the Jevons paradox - improvements of efficiency in a technology might not decrease resource usage due to increased demand brought about by lower costs. An example of this is shown in the chart from Menlo ventures, which shows that spending by enterprises has not necessarily slowed as models have become more efficient, they just use bigger models.
The resource causing the tightest constraint is quickly becoming electricity. Data centres accounted for 1% of electricity usage in the US at the start of the decade (order of magnitude). It is projected to be 10% by the end of the decade. Adding capacity to the grid can be difficult (for reasons we don't nearly have time to go into), but suffice to say that this may well become enough of an issue that in the future tokens could well be priced based on the marginal cost of electricity alone. I think this would have profound consequences for the industry and how it interacts with society.
Conclusion: What Builders Should Really Care About
This set of interrelated issues and questions is what AI companies should really be worried about when we talk about a bubble - what will the performance, but especially the cost of models look like going forward. Individuals who like to use AI tools (quite a lot of us, even if people won't admit it) should also think about this. Our AI usage is being heavily subsidised and if the bubble pops, this is going to end. When building AI tools we really need to think about how much a token is going to cost in the future and how well we can use it.