
In modern artificial intelligence, one of the most captivating progressions is the emergence of generative AI. Generative AI enables machines to generate texts, images, videos, and music that closely resemble human creations. Generative AI works on the principle that when an input is given, it produces meaningful output based on the available pre-trained models. They are changing the way of creating content and solving problems.
The global leading Cloud Provider, Amazon Web Services (AWS), launched a platform called AWS Bedrock in 2023. AWS bedrock is a fully managed service that eases the building of generative AI applications by using foundation models (FMs) such as Cohere, Claude, etc. Foundation models are pre-trained models available in the market, trained by leading AI companies such as Cohere, Anthropic, Stability AI, etc.
Amazon Bedrock provides a platform to experiment, assess, and customize these foundation models privately with your data. One of the prominent features of Bedrock is model inference. This feature allows developers to seamlessly integrate the customized foundation models with their applications, allowing them to generate content and assist users in real time. It opens up many possibilities for user experience optimization and automation. Since Bedrock is a fully managed service, developers can create AI applications without the burden of infrastructure management. This speeds up the development and deployment process of the AI applications.
Knowledge Base for Bedrock
Before creating the generative AI applications, assemble the data for your use case. A knowledge base provides the capability to gather data sources into a repository of information. With knowledge bases, you take advantage of Retrieval Augmented Generation, a technique involving retrieval of information from data stores and enhances the responses generated by Large Language models (LLMs). When you set up a Knowledge Base for your data sources, your application can query the Knowledge Base and either answer your query or return natural responses of the query results. Please note that if the answers are inaccurate, you can customize the model with only Amazon’s Titan as the Foundation Model.
Creating Knowledge Base
- Go to Amazon Bedrock service in the AWS console, click on Knowledge Base in the left navigation panel, and then click Create Knowledge Base.

- Enter a name for your Knowledge Base. Create a new role, or use an existing role for your Knowledge Base and click on Next.
- Enter the name of your data source and then enter S3 URI where your data is present. Choose No chunking to avoid splitting your files further by Bedrock, and click Next.

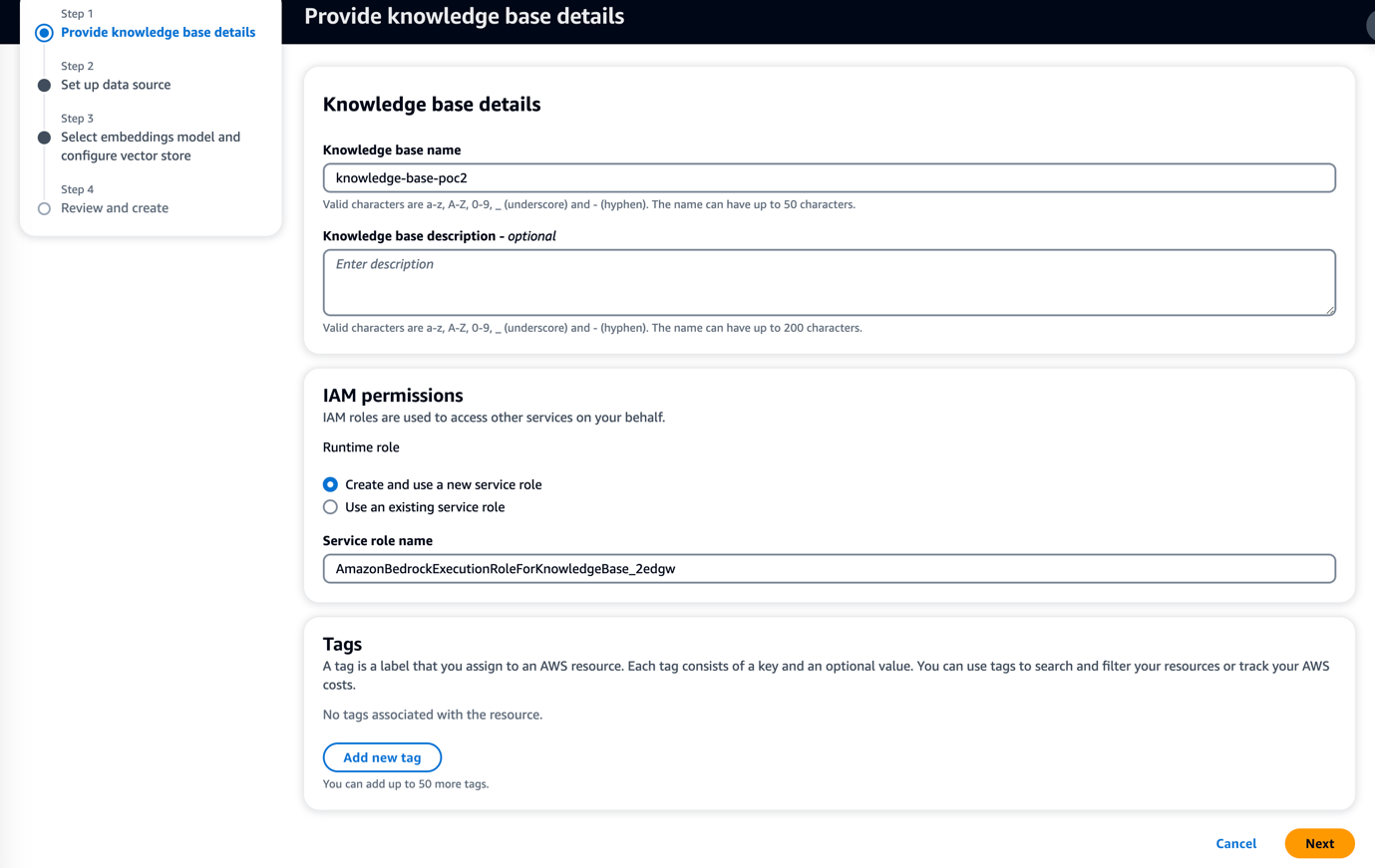
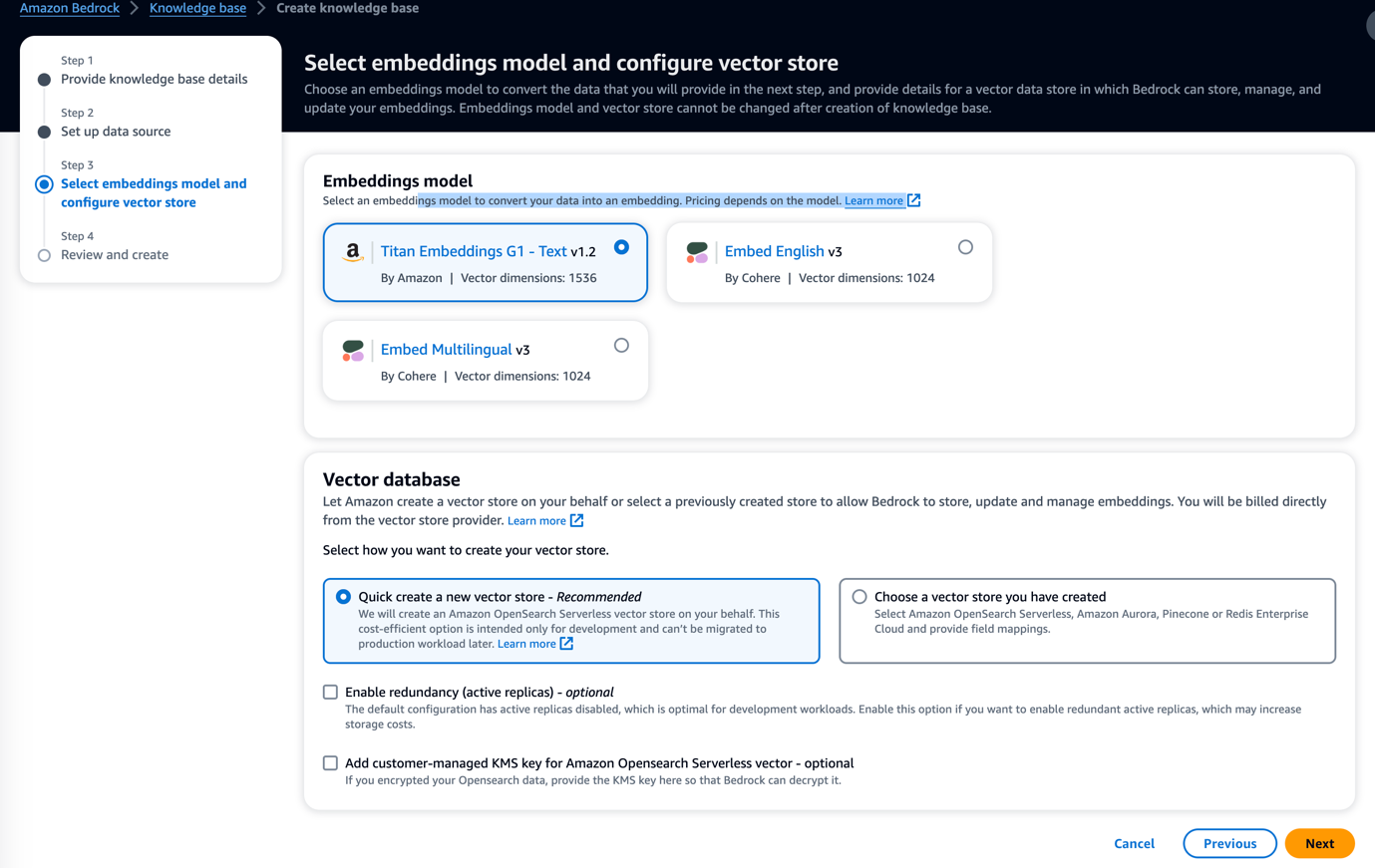
- Select the Embeddings Model or Foundation Model and Vector database for your requirement, and then click Next to review and click Create Knowledge Base. Note that the Embeddings Model and Vector base are unchangeable once after Knowledge Base creation.
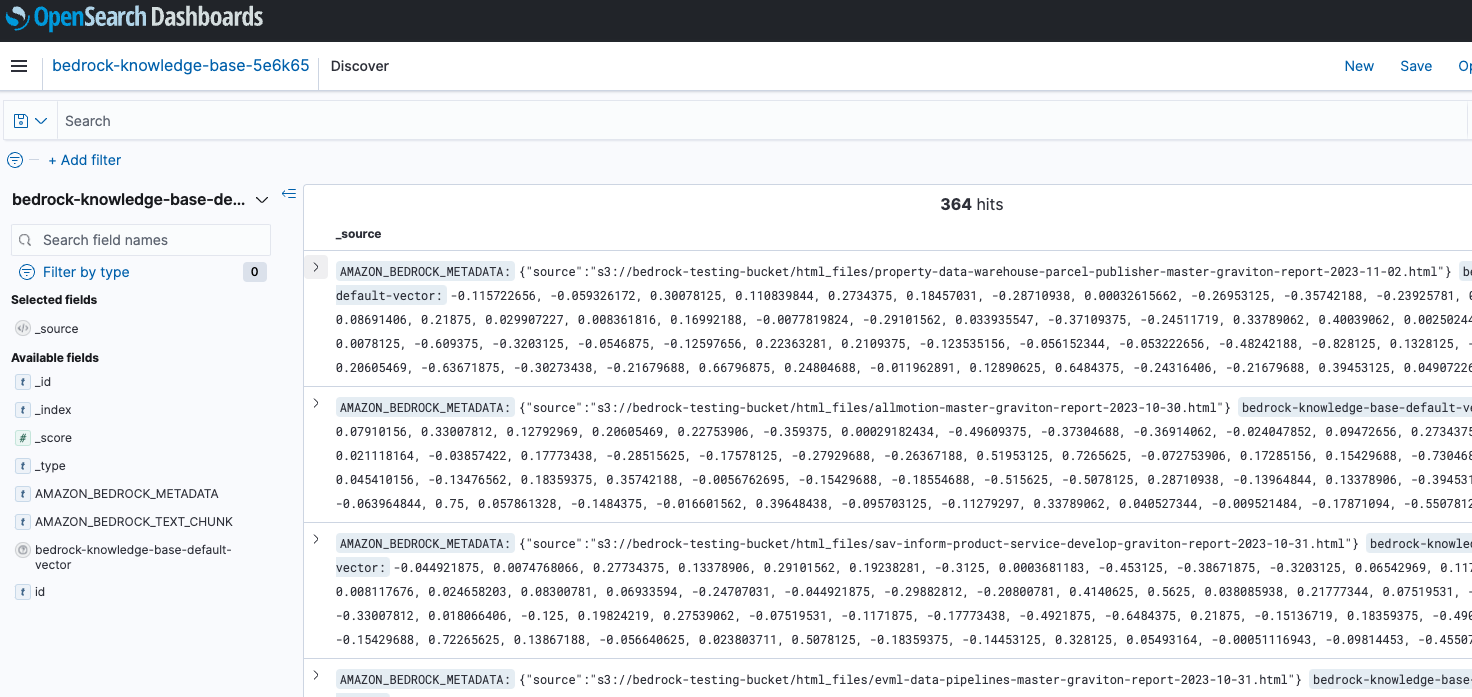
5. After Knowledge Base creation, Bedrock will sync all the files from S3 uri to your Knowledge Base. Bedrock also creates an OpenSearch as we chose a new vector store and logged all the S3 files to OpenSearch as shown in Figure1.5

Testing the knowledge base
- Go to your Knowledge Base and click Test. Click on Select model, choose a model for querying, and then Apply.
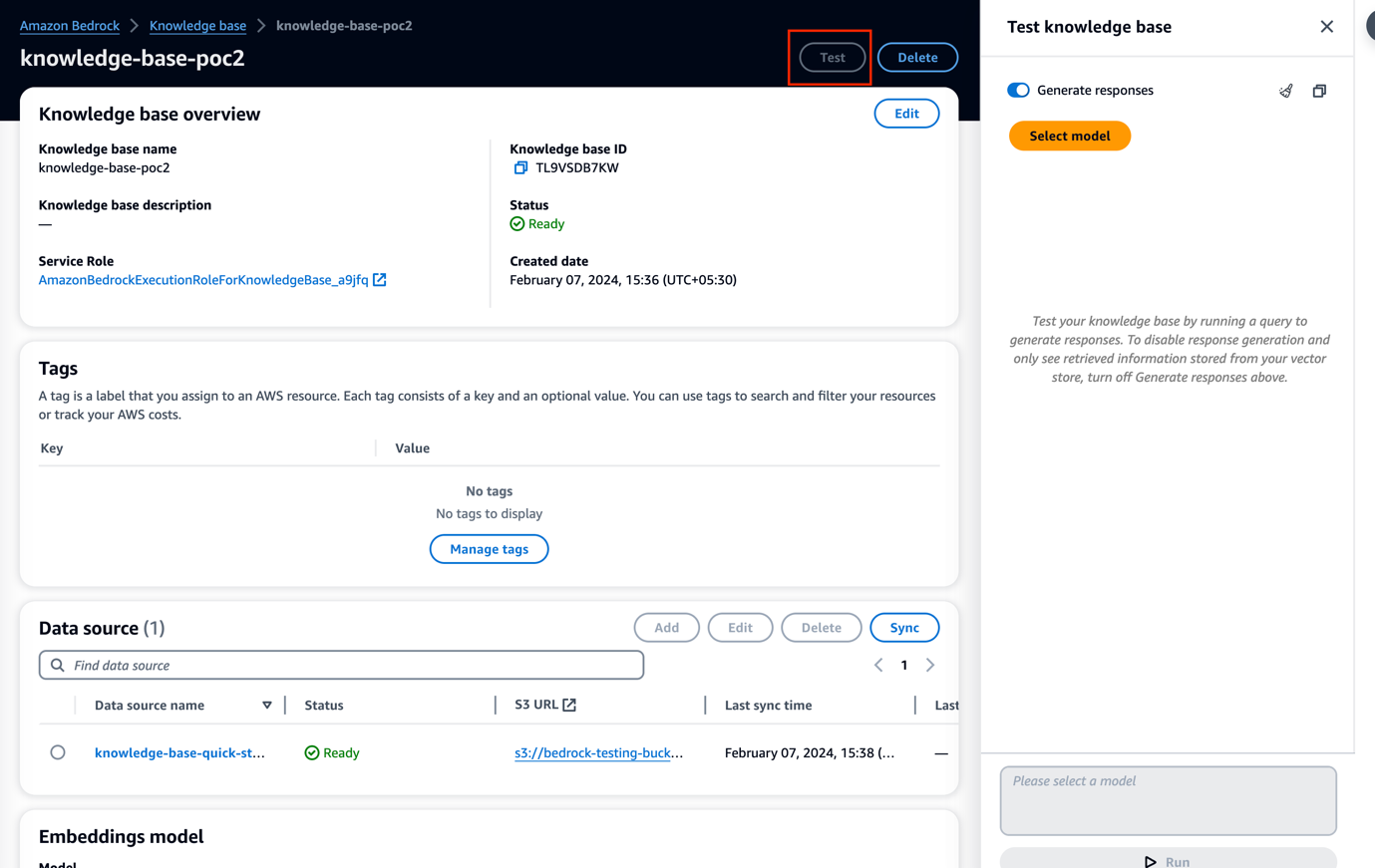

You can see that in Figure 1.9 and Figure 1.10, the model can retrieve the results for the given inputs. However, the model lacks intelligence to understand if the query is unclear. This is where model customization comes into the picture.

Agents in Bedrock
Agents orchestrate interactions between Foundation Models, data sources, software applications, and user conversations. It automatically calls API to complete end-user actions by invoking knowledge bases for information.Creating an agent
1. Go to Agents in the left navigation panel of the bedrock console. Give a name to your agent, enter the details based on your requirements, and click Next.
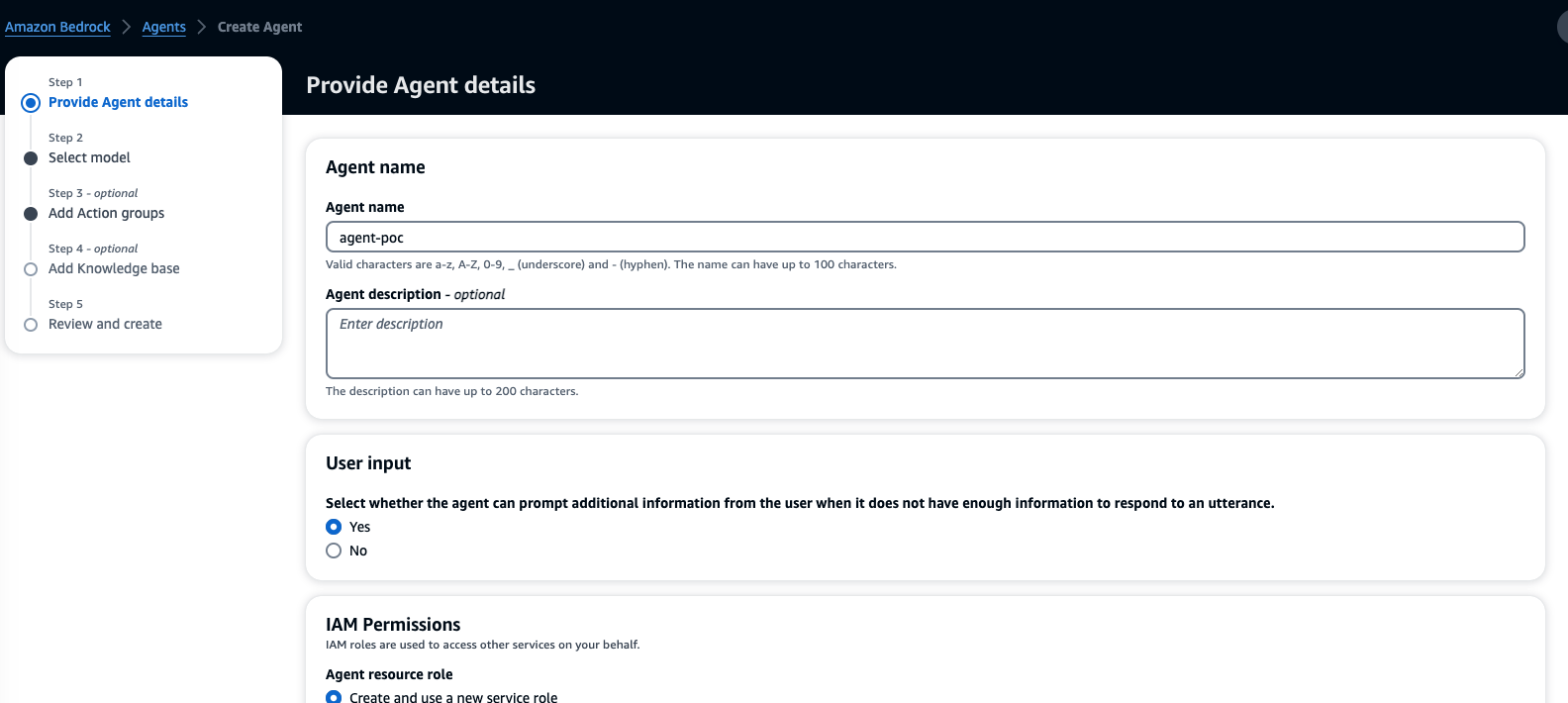
2. Select the model, give the instructions for the agent to perform tasks as shown in Figure 2.2, and click Next.
3. Add action groups to perform actions by agents automatically. Define business logic to perform actions in the lambda function, and define Open API schema for your agent in the S3 bucket. You can refer to the files below to understand how to define the schema and lambda function.
https://github.com/aws-samples/amazon-bedrock-workshop/blob/main/07_Agents/insurance_claims_agent/without_kb/insurance_claims_agent_openapi_schema.json
https://github.com/aws-samples/amazon-bedrock-workshop/blob/main/07_Agents/insurance_claims_agent/without_kb/lambda_function.py

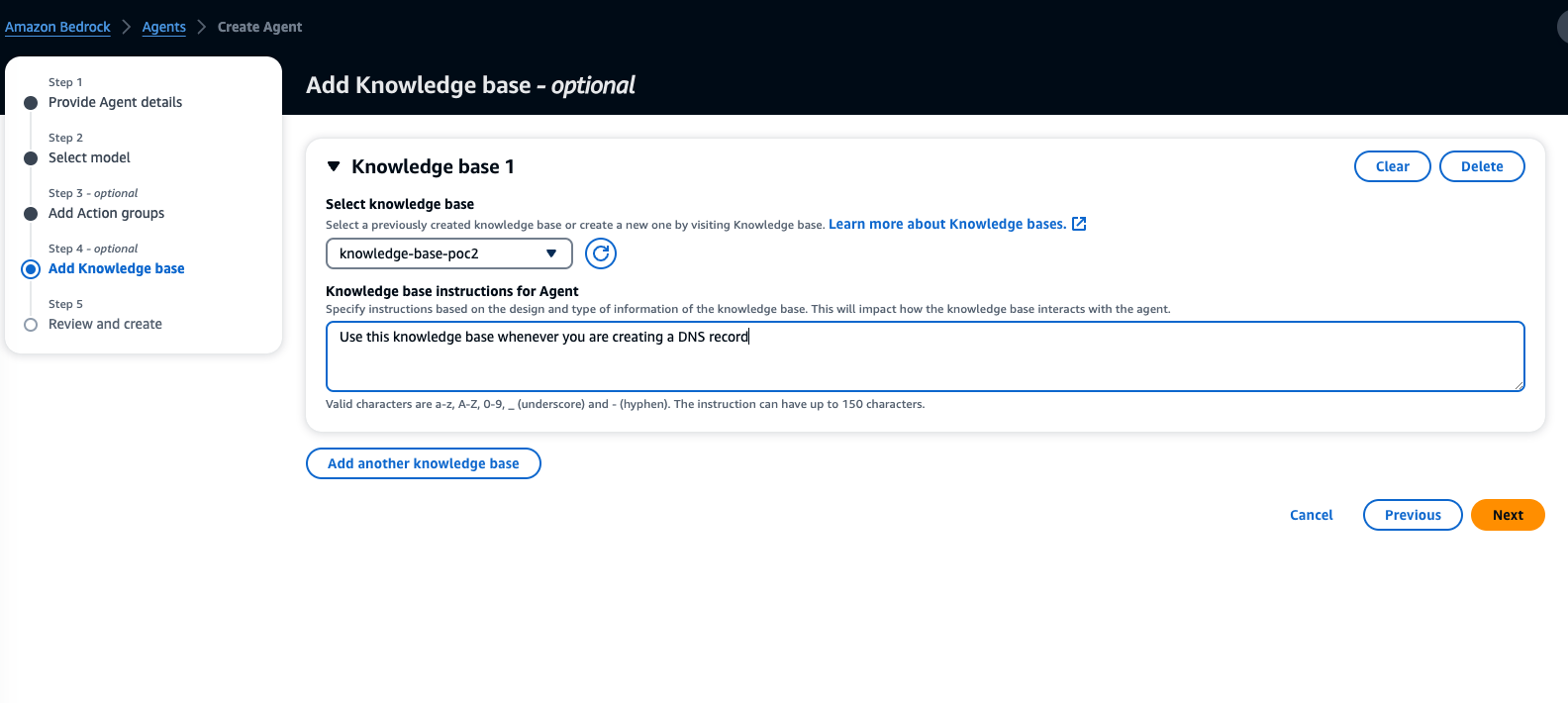
4. Add the Knowledge Base, provide instructions for the agent, click Next to Review, and click Create Agent.

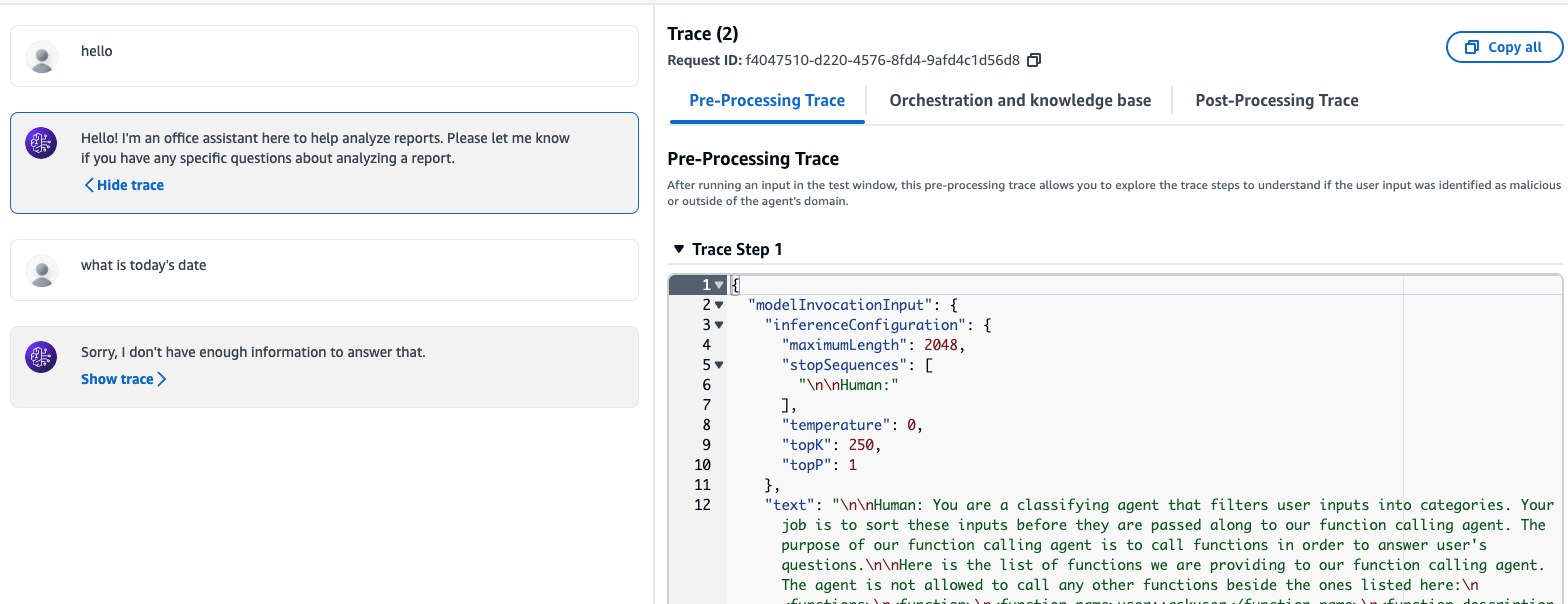
5. Click Agent and enter your queries to test whether the agent can perform the tasks according to your business logic. You can click on show trace and trace the API calls.
Custom models
In the tech domain, one AI model approach does not suit all use cases. In such scenarios, fine-tuning or a little pre-training of models would help achieve the desired results. Bedrock allows two types of customization: Fine-tuning and Continued pre-training.Fine-tuning: It labels the training data and enhances the model’s performance.Continued pre-training: It adds domain-specific knowledge to your AI that is absent in base models.
Creating custom models
1. Prepare a training dataset with user queries and corresponding answers. Here’s a snippet of sample training data in JSON format:
{"prompt": "What are the features of product X?", "completion": "Product X offers a range of features including..."}
{"prompt": "How can I contact customer support?", "completion": "You can reach our customer support team at..."}
{"prompt": "Tell me about pricing for service Y.", "completion": "Service Y has flexible pricing plans..."}
2. Customisation can be achieved by uploading your training and validation datasets to Amazon S3. Go to custom models in the bedrock console, click Create a custom model, and choose Create fine-tuning job or Create Continued pre-training job.
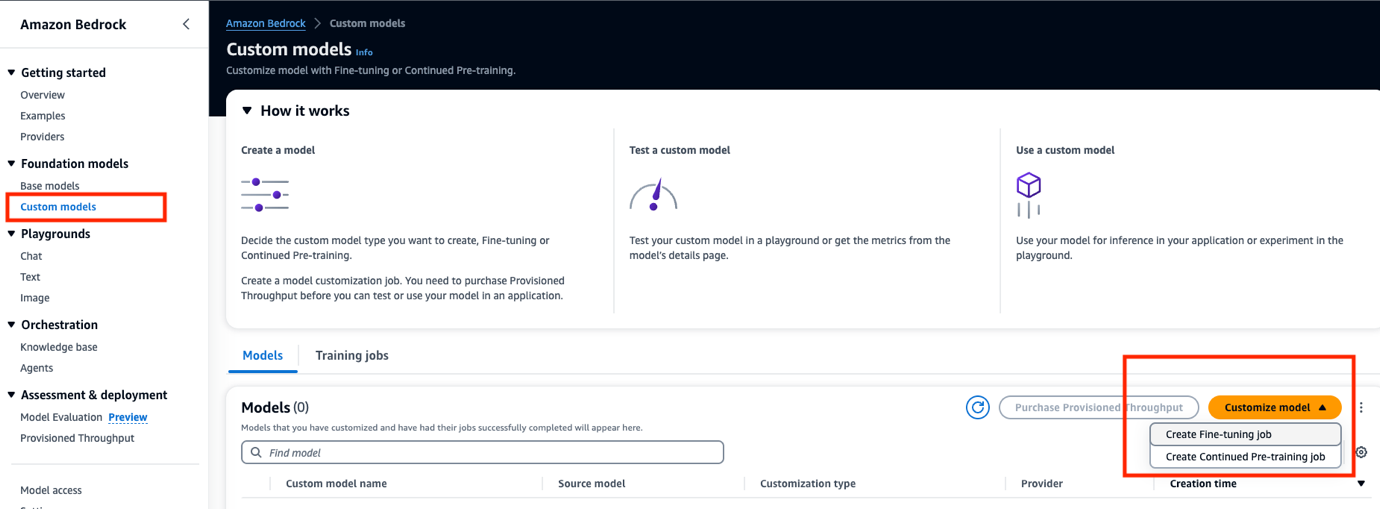
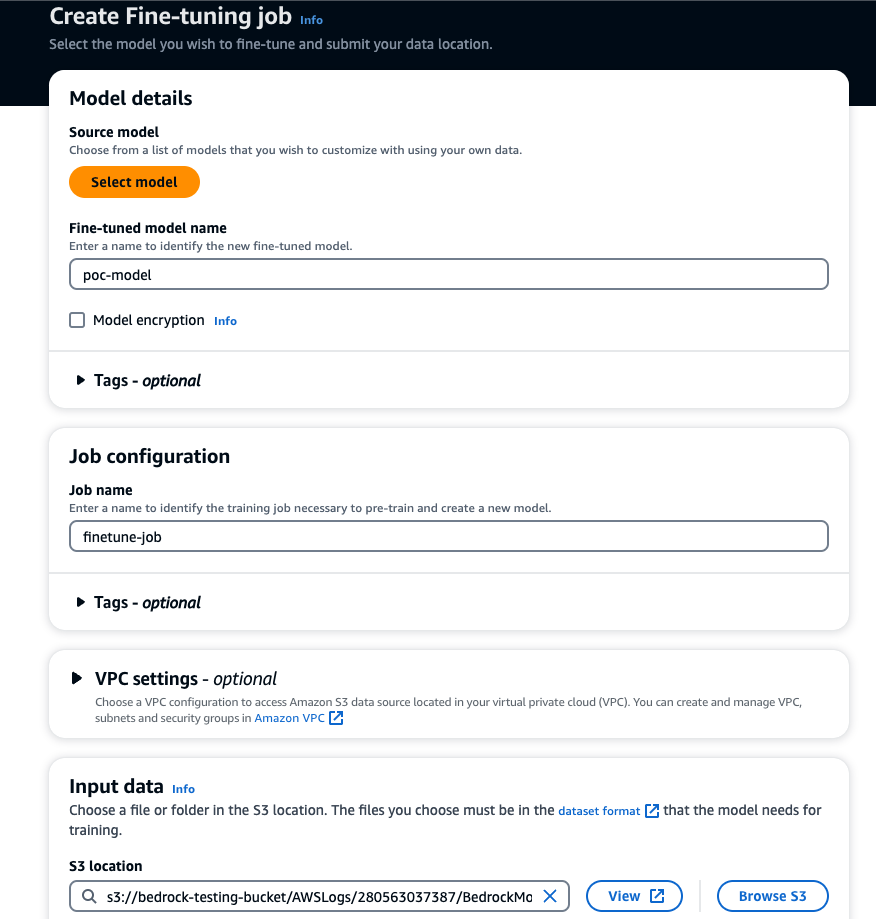
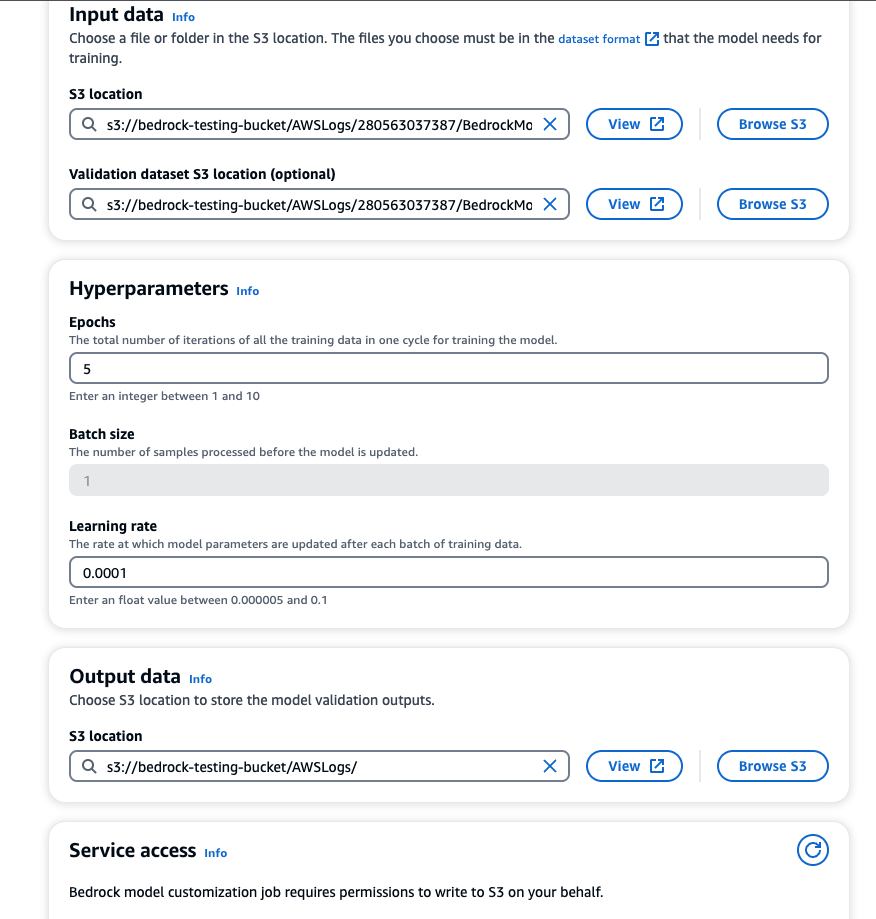
3. Click on Select model to choose the base model. Enter model name, job name, training, and validation datasets location, configure hyperparameters, add S3 location to store output for model validation, and service role for Bedrock to access S3.
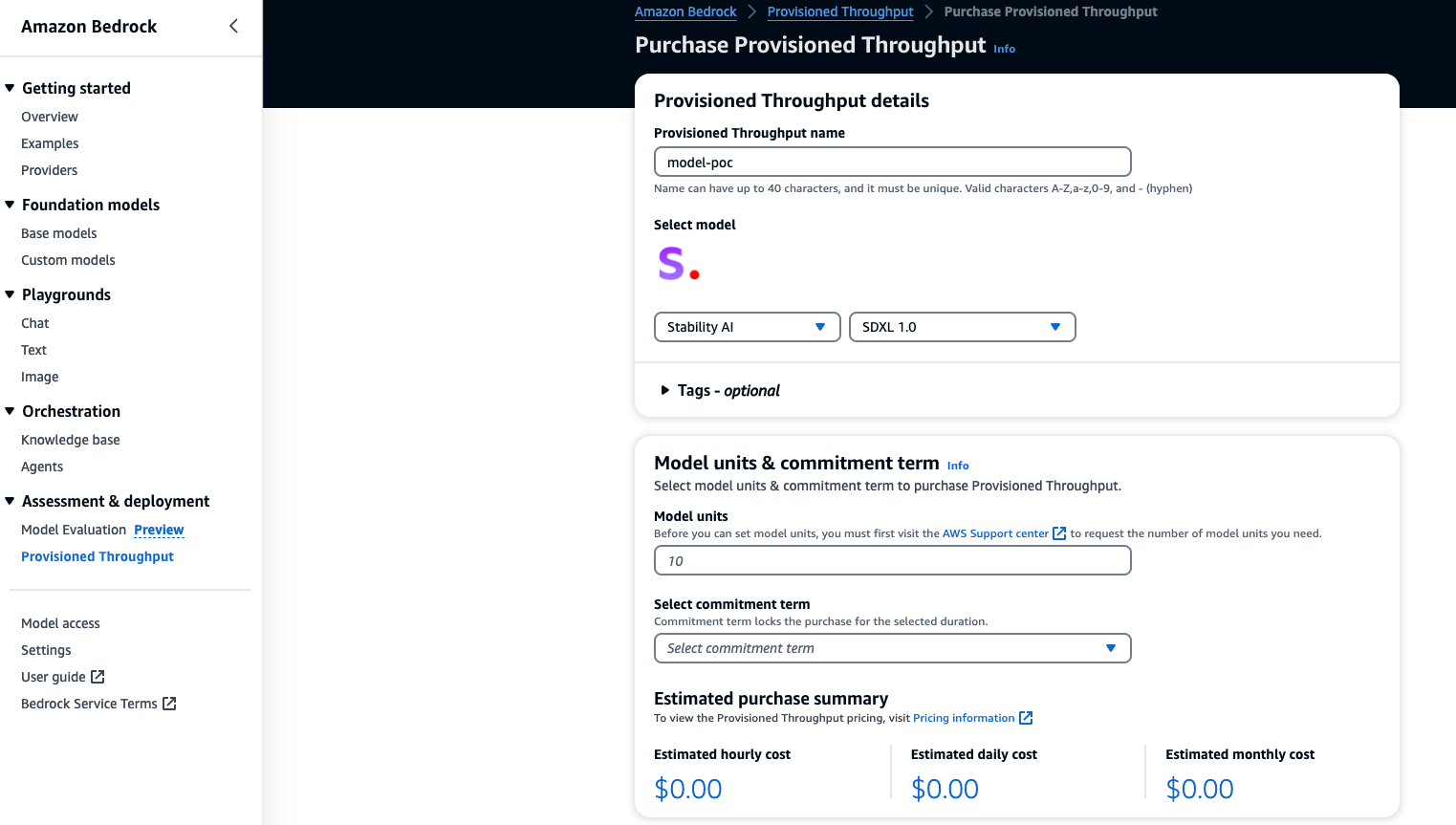
After creating a custom model, you must purchase Provisioned Throughput to test or use the model. Start the training job under custom models.
Analyzing the model
Once the model customization job is completed, you can analyze the training results by looking at the S3 files stored in the output S3 folder mentioned during fine-tuning job creation. You can also run a model evaluation job to analyze the results.
In a nutshell, Amazon Bedrock serves more than a platform and is a doorway to the new era of generative AI applications. It assists developers in leveraging the capabilities of AI effortlessly and securely. The concept of foundation models, extensive customization, and creating an AI ecosystem is exceptional. Whether it is creating your chatbots, expanding AI functionalities, or integrating AI models, Bedrock serves as a trustworthy companion in unlocking the full potential of generative AI.